Интеллектуальный анализ данных (Data Mining) - совокупность методов поиска полезных знаний в больших объемах данных. Методы ИАД применяются в таких сферах человеческой деятельности как научные исследования, бизнес и государственная безопасность.
Термин впервые введен Григорием Пятецким-Шапиро (Gregory Piatetsky-Shapiro) в 1989 г. Наряду с Data Mining в качестве синонима применяется термин Knowledge Discovery in Databases (KDD).
Целью методов Data Mining является обнаружение ранее неизвестных, нетривиальных, практически полезных знаний.
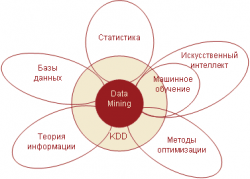
Методы ИАД лежат на стыке таких направлений как искусственный интеллект (нейронные сети и машинное обучение), математическая статистика и теория баз данных.
Григорий Пятецкий-Шапиро - один из основоположников этого направления. Он ввел термин Data Mining и дал ему следующее определение: "Data Mining - это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности". Организовал ряд научных конференций посвященных анализу данных. Автор более 60 научных статей.
История
На протяжении столетий человечество занималось ручным поиском закономерностей и шаблонов (паттернов) в данных. К первым методам выявления шаблонов в данных относятся Теорема Байеса и Регрессионный анализ.
В 80-е годы ХХ века появились первые реляционные базы данных и язык запросов. Специалистов по базам данных интересовали вопросы ускорения запросов к базам данных. Технологии анализа данных развивались в основном в рамках прикладной статистики.
С развитием вычислительной техники предприятия стали производить и сохранять большие объемы данных о своей деятельности. В 90-е годы появляются технологии хранилищ данных (Data Warehousing). Это привело к увеличению интереса к методам анализа данных в первую очередь со стороны бизнеса.
В основе современных технологий Data Mining лежит концепция шаблонов, представляющих собой закономерности в данных, которые могут быть представлены в понятной человеку форме.
Задачи
Задачи, решаемые методами Data Mining, принято разделять на описательные и предсказательные.
В описательных задачах самое главное - это дать наглядное описание имеющихся скрытых закономерностей, в то время как в предсказательных задачах на первом плане стоит вопрос о предсказании для тех случаев, для которых данных еще нет.
К описательным задачам относятся:
- поиск ассоциативных правил;
- кластерный анализ;
- построение регрессионной модели.
К предсказательным задачам относятся:
- классификация объектов (для заранее заданных классов);
- регрессионный анализ, анализ временных рядов.
Сферы применения
Розничная торговля
- анализ покупательской корзины (анализ сходства)
Позволяет выявить товары, чаще всего покупаемые совместно. Это способствует выработке более эффективной рекламы, подходов к раскладке товаров в торговых залах.
- исследование временных шаблонов
Помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа "Если сегодня покупатель приобрел видеокамеру, то через какое время он вероятнее всего купит новые батарейки и пленку?"
- создание прогнозирующих моделей
Дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
Банковское дело
- выявление мошенничества с кредитными карточками.
- сегментация клиентов.
Позволяет сделать маркетинговую политику более результативной.
- прогнозирование изменений клиентуры.
Data Mining помогает банкам строить прогнозные модели ценности своих клиентов, и соответствующим образом обслуживать каждую категорию.
Телекоммуникации
- анализ записей о подробных характеристиках вызовов
Назначение - выявление категорий клиентов с похожими стереотипами пользования их услугами и разработка привлекательных наборов цен и услуг.
- выявление лояльности клиентов.
Data Mining можно использовать для определения характеристик клиентов, которые, один раз воспользовавшись услугами данной компании, с большой долей вероятности останутся ей верными. В итоге средства, выделяемые на маркетинг, можно тратить там, где отдача больше всего.
Страхование
- выявление мошенничества.
Сводится к отысканию определенных стереотипов в заявлениях о выплате страхового возмещения.
- анализ риска.
Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам.
Другие приложения в бизнесе
Data Mining может применяться во множестве других областей:
- развитие автомобильной промышленности. Возможность прогнозирования популярности определенных характеристик и знание того, какие характеристики обычно заказываются вместе;
- политика гарантий.
- поощрение часто летающих клиентов. Авиакомпании.
Также Data Mining применяется в медицине, молекулярной генетике и генной инженерии, прикладной химии и в других областях.
Типы закономерностей
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование.
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и "кока-колу", а при наличии скидки за такой комплект "колу" приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
Перспективы
С развитием методов ИАД все чаще возникают озабоченности по поводу неприкосновенности частной жизни. Коммерческие базы данных, зачастую, хранят медицинскую документацию, данные о телефонных переговорах, финансовую информацию и многие другие данные, касающиеся различных аспектов частной жизни людей. Возрастают риски злонамеренного использования методов анализа данных. В ближайшей перспективе предстоит решать вопросы общественного контроля над применением результатов анализа.
Источники:
1. ru.wikipedia.org
2. inftech.webservis.ru/it/database/datamining/ar2.html
3. Encyclopædia Britannica, 2014
4. Паклин Н.Б., Орешков В.И Бизнес-аналитика от данных к знаниям: учебное пособие. 2-е изд., испр. - СПб.: Питер, 2013. - 704 с.: ил.